A security service sounds clean until it lands in a real CI/CD environment. Then it becomes a pile of scanners, workflow exceptions, Slack alerts, ignored SARIF, and one engineer who knows why the release job still has write-all permissions.
Teams think the problem is finding more vulnerabilities. The real problem is making security decisions at the point where software supply-chain risk is introduced.
That changes the conversation. A security service for DevSecOps is not a dashboard. It is an enforcement path across pull requests, GitHub Actions, package manifests, workflow permissions, secrets boundaries, and release automation.
The practical question is not whether you have security tooling. It is whether your tooling can say no, say why, attach evidence, route ownership, and let the right exception expire before it becomes permanent infrastructure.
Table of contents
- Security service is an operating model, not a product category
- Where the security service sits in the delivery path
- Signals a CI/CD security service must collect
- The workflow: from change to decision
- Security service vs scanner vs platform
- Common failure modes
- What works in production
- Integration details DevSecOps teams should design
- Metrics that prove the service is helping
- Product fit: vu1nz.com as a CI/CD security service layer
- Closing: make the security service enforceable
Security service is an operating model, not a product category
What the phrase usually hides
Most teams use security service as a vague umbrella. It can mean managed detection, vulnerability management, cloud posture, endpoint monitoring, or an internal platform team that glues scanners together. In CI/CD, that ambiguity is expensive.
The mistake teams make is treating the service as a place where findings go after engineers have already made the risky change. A package gets added, a workflow gets modified, a token permission expands, and the service reports it later. That is reporting, not control.
A useful way to think about it is this: a security service is a decision system. It takes signals from engineering activity, evaluates them against risk rules, and produces one of a few operational outcomes: allow, warn, block, escalate, or grant a time-bound exception.
That framing matters because it forces architecture questions:
- Where does the service observe change?
- What context does it need to avoid false positives?
- Who owns the decision when a check fails?
- How does an exception expire?
- How do you prove the control ran on the commit that merged?
If those questions are unanswered, the service becomes another notification layer.
Why CI/CD changes the boundary
Traditional security programs often assume risk enters through deployed infrastructure, exposed applications, or known vulnerable dependencies. Modern software supply-chain attacks do not respect that boundary. Risk can enter through a contributor token, a poisoned package, a workflow pull_request_target mistake, a compromised maintainer, or a release job that trusts unreviewed artifacts.
CI/CD turns source control into an execution environment. GitHub Actions is not just automation around code. It is a permissioned runtime with secrets, tokens, artifacts, caches, third-party actions, and deploy credentials.
Practical rule: If a workflow can build, sign, publish, or deploy software, it is part of your production attack surface.
A CI/CD security service therefore has to sit closer to engineering changes than most vulnerability management programs were designed to operate. It should understand pull requests, workflow diffs, package manifests, lockfile behavior, repository settings, and the difference between a harmless lint job and a release path with privileged credentials.
Where the security service sits in the delivery path
Pull request as the control point
The pull request is the most useful control point because it is where risk is still negotiable. Before merge, engineers can remove a package, pin an action, reduce a token permission, or split a risky workflow into a separate approval path. After merge, the same issue becomes an incident, a hotfix, or a backlog item.
A security service should attach itself to the same lifecycle developers already use:
- A PR opens or updates.
- The service computes the diff across code, workflows, package manifests, and lockfiles.
- It evaluates only the risk introduced or changed by that PR.
- It returns a check result with evidence.
- The repository policy decides whether that check is required to merge.
That last point is where architecture becomes governance. If the service is advisory only, it may still be useful. But for high-risk classes, advisory controls degrade quickly. The service needs a merge gate for findings that represent direct supply-chain compromise paths.
For GitHub-native teams, a drop-in approach is often the lowest-friction starting point. The vu1nz GitHub Action for CI/CD and package security is designed around that PR boundary: scan workflow risk and newly added packages where the change is introduced, not three weeks later in a dependency dashboard.
Runtime findings are too late for package risk
Runtime detection is still necessary. But it is the wrong first line for many package and CI/CD problems.
If a malicious dependency lands in a build path, it may run install scripts during CI. If a workflow exposes secrets to untrusted code, the damage can happen before the application is deployed. If an attacker modifies a release job, the artifact can be poisoned while every runtime detector is still waiting for the next container to start.
What breaks in practice is the assumption that deployment is the first meaningful execution event. In software supply chains, install, build, test, package, and publish are execution events too.
Practical rule: Treat CI execution as production-adjacent execution when credentials, signing keys, deploy tokens, or publish rights are available.
This does not mean every PR should be blocked for every theoretical issue. It means the service must classify where the change can execute and what authority that execution has.
Signals a CI/CD security service must collect
Workflow and permission signals
A security service that cannot parse workflow changes is blind to a large part of modern delivery risk. The minimum useful signal set includes:
- Trigger changes, especially pull_request_target, workflow_run, schedule, and repository_dispatch.
- Token permission changes, including write-all, contents write, packages write, actions write, and id-token write.
- Third-party action usage, pinning, and version drift.
- Secret exposure paths through environment variables, shell interpolation, artifacts, and logs.
- Use of privileged runners, self-hosted runners, and deployment environments.
- Artifact upload and download boundaries across jobs and workflows.
The service should not just grep YAML. It needs to reason about how the workflow executes. A permissions block on a job matters differently than one at the workflow root. A dangerous trigger is more dangerous when it combines with secrets, untrusted checkout, or writable tokens.
A practical policy might look like this:
rules:
block:
- pull_request_target_with_untrusted_checkout
- write_all_permissions_on_pr
- unpinned_third_party_action_in_release_job
warn:
- broad_contents_write_outside_release
- artifact_download_from_untrusted_workflow
require_review:
- id_token_write_added
- self_hosted_runner_added
The names are less important than the model. Block direct compromise paths. Warn on hygiene. Require human review for authority expansion.
Package and dependency signals
Known CVEs are only part of dependency risk. The uncomfortable part is that many supply-chain incidents are not known-vulnerable packages. They are new packages, typosquats, maintainer takeovers, postinstall behavior, dependency confusion, token stealers, obfuscated code, or packages that suddenly change behavior.
That is why a CI/CD security service needs package-introduction awareness. It should ask:
- Is this package new to the repository?
- Is it new to this ecosystem or unusually young?
- Does it run install scripts?
- Does it include obfuscated payloads or encoded network calls?
- Does it request suspicious capabilities for its ecosystem?
- Did the lockfile resolve to a different package or source than expected?
- Is the package added only in devDependencies but still executed in CI?
Dependabot-style tooling has a place, but it is not enough for zero-day package abuse. We covered that gap in detail in What Dependabot Misses, especially the cases where no CVE existed when the attack reached production.
Related reading from our network: SOC teams face a similar signal-to-decision problem in synthetic content monitoring, and the workflow framing in AI content threat detection maps well to CI/CD triage: signals are cheap, validated decisions are the hard part.
Repository and contributor signals
Code context matters. The same dependency addition can mean different things depending on where it appears and who introduced it.
Useful repository signals include:
- Is the PR from a fork?
- Is the author a first-time contributor?
- Does the PR modify release, deployment, or package publishing paths?
- Does it touch CODEOWNERS, branch protection, or security configuration?
- Does it add a new package manager file?
- Does it combine workflow changes with dependency changes?
Be careful with contributor signals. They should inform risk, not become a lazy trust score. Long-time maintainers get phished. New contributors can submit legitimate fixes. The service should use identity and history to route review and adjust scrutiny, not to automatically bless dangerous changes.
The workflow: from change to decision
A practical implementation sequence
A security service becomes real when it has a repeatable path from event to action. Start simple, then tighten.
- Inventory protected repositories. Identify repos that build, publish, deploy, sign, or handle sensitive credentials.
- Map privileged workflows. Find release jobs, deployment jobs, package publishing, container publishing, and OIDC federation.
- Define merge-risk classes. Decide what must block, what warns, and what requires security review.
- Install PR-time scanning. Run on pull_request for code and package diffs. Be careful with pull_request_target.
- Require checks on protected branches. Start with critical repos rather than every repo.
- Route failures to owners. Use CODEOWNERS, security reviewers, or service ownership metadata.
- Add exception workflow. Require reason, owner, expiration, and compensating control.
- Review bypasses weekly. Remove stale exceptions and tune noisy rules.
This sequence avoids the usual big-bang platform rollout. You do not need perfect coverage on day one. You need enforceable coverage on the paths where compromise would matter.
Practical rule: Enforce narrowly before you alert broadly. A small number of reliable merge gates beats a large number of ignored warnings.
Decision states that do not create noise
Binary pass or fail is too blunt for CI/CD security. A useful service should produce operational states that match how teams actually work:
- Pass: no relevant risk introduced by this change.
- Warn: risky pattern detected, but not enough authority or exploitability to block.
- Block: direct compromise path or policy violation.
- Needs owner review: authority expansion or sensitive area change.
- Needs security review: ambiguous but potentially high-impact change.
- Exception active: approved temporary bypass with expiration.
- Not applicable: rule skipped because the repo lacks the relevant path.
The value is not in inventing more labels. The value is reducing useless escalation. A warning should not page security. A block should not require five humans to interpret. A review state should name the owner and the evidence.
Security service vs scanner vs platform

Comparison table
Teams often buy a scanner and call it a security service. Sometimes that is fine for narrow use cases. But if the goal is CI/CD and software supply-chain defense, the difference matters.
| Capability | Standalone scanner | Security platform | CI/CD security service |
|---|---|---|---|
| Primary unit | Finding | Asset or application | Change and merge decision |
| Best at | Detecting known patterns | Centralizing visibility | Enforcing workflow risk policy |
| Typical timing | After scan trigger | Scheduled or event-based | PR and release path |
| Context needed | File or dependency | Asset inventory | Workflow authority, package diff, repo policy |
| Output | Report or alert | Dashboard and ticket | Check result, evidence, exception path |
| Failure mode | Noise | Slow governance | Bad blocking if rules lack context |
| Ideal owner | Tooling or AppSec | Security platform team | DevSecOps plus repo owners |
A scanner is an engine. A platform is a system of record. A security service is the operating path that turns signals into decisions engineers cannot accidentally ignore.
Where point tools still fit
Point tools are not bad. They are often the best component for a specific signal. Static analysis, secret scanning, dependency vulnerability scanning, malware detection, IaC checks, and artifact signing all matter.
The mistake teams make is expecting each tool to own the workflow. Then every tool invents its own severity, UI, exception model, and ownership routing. Developers receive conflicting messages. Security loses track of what was waived. Engineering managers only notice when a release is blocked without context.
A better pattern is to let point tools feed the service, while the service owns policy, state, evidence, and enforcement.
Related reading from our network: architecture-heavy teams outside security run into the same tool-versus-operating-model issue; computer systems technology for streaming and home media is a useful adjacent example of why storage, network, privacy, and workflow decisions cannot be solved by one component alone.
Common failure modes
Alert piles without ownership
The most common failure is a feed of findings with no owner. Security says the repo team owns it. The repo team says the platform team owns the workflow. The platform team says the package was added by an application engineer. The application engineer says the scanner did not explain why it matters.
This is how supply-chain findings die.
A service needs ownership primitives:
- Repository owner.
- Workflow owner.
- Package owner or dependency steward.
- Security reviewer.
- Exception approver.
- Business or service criticality.
If you cannot route a finding, you cannot enforce it consistently.
Blocking without context
The opposite failure is overblocking. A service flags every unpinned action, every new package, every broad permission, and every shell script as a merge blocker. Developers quickly learn to route around it.
Blocking should be reserved for patterns where the service can explain the attack path. For example:
- Untrusted PR code can execute in a privileged workflow.
- A token with write permissions is exposed to a fork-controlled context.
- A newly added package has suspicious install behavior and executes during CI.
- A release workflow starts consuming artifacts from an untrusted workflow.
- A third-party action in a publishing job is referenced by a mutable tag.
Warnings can cover broader hygiene. Blocks should be precise.
Trusting lockfiles too much
Lockfiles help reproducibility, but they are not a complete trust boundary. They can hide transitive changes, point to unexpected sources, or normalize a malicious resolution after the first compromised install. They also do not answer whether the package itself is safe.
What breaks in practice is assuming that a lockfile diff is boring. In many attacks, the lockfile is the evidence.
A CI/CD security service should inspect manifests and lockfiles together. It should understand when a new direct dependency pulls a suspicious transitive tree, when a registry source changes, and when a package with install scripts enters a path that runs before tests.
What works in production
Start with merge-risk classes
Do not start with a thousand rules. Start with a handful of merge-risk classes that represent real compromise paths.
Good initial classes include:
- Privileged workflow triggered by untrusted code.
- New package with suspicious behavior added to a build path.
- Release workflow uses mutable third-party actions.
- PR expands token permissions on protected workflows.
- Self-hosted runner introduced or exposed to forked PRs.
- Artifact trust boundary removed between build and release.
These classes are specific enough to explain and broad enough to cover common failures.
A useful way to think about it is to write the policy in attacker language. Not just critical severity, but attacker can run code with a token that can publish a package. That sentence is understandable to engineers and executives.
Make exceptions expire
Permanent exceptions are usually undocumented architecture decisions. Some are valid. Most are forgotten.
Every exception should include:
- Rule name.
- Repository and workflow scope.
- Reason.
- Approver.
- Expiration date.
- Compensating control.
- Link to tracking issue if remediation is not immediate.
For example:
exception:
rule: unpinned_third_party_action_in_release_job
repo: payments-api
workflow: release.yml
expires: 2026-07-15
approver: appsec-oncall
reason: upstream action pin migration in progress
compensating_control: release requires protected environment approval
The service should fail closed when the exception expires. If that is too disruptive, at least downgrade it to needs security review. Silent expiry is how temporary risk becomes standard practice.
Keep evidence close to the PR
Developers should not have to open a separate platform, search for a scan, infer which commit it belongs to, and guess what changed. Put the evidence where the decision is happening.
Effective PR evidence includes:
- The exact workflow lines that changed.
- The permission or trigger that creates risk.
- The package name, version, source, and suspicious behavior.
- The execution path showing when it runs.
- The policy that caused the result.
- The remediation options.
This reduces security review time because the reviewer is not reconstructing context. It also reduces developer frustration because the service explains the rule in the language of the change.
Integration details DevSecOps teams should design
GitHub Actions permissions
GitHub Actions security is mostly about combinations. A single setting may look acceptable until it is paired with the wrong trigger, checkout pattern, or token scope.
At minimum, your service should evaluate:
permissions:
contents: read
pull-requests: read
id-token: none
Then identify deviations that matter:
- write permissions on PR-triggered jobs.
- id-token write added outside a trusted deployment flow.
- contents write combined with untrusted checkout.
- actions write in workflows that can be influenced by contributors.
- packages write in build jobs that consume unreviewed artifacts.
The default posture should be least privilege. But the service also needs to understand legitimate release flows. OIDC with id-token write may be correct in a deployment job with environment protection and branch restrictions. It is risky in a generic PR workflow.
Webhooks, retries, and idempotency
If you build the service internally, treat CI/CD security as an event-driven system. Webhooks arrive more than once. Jobs are retried. Commits are force-pushed. Checks may complete out of order. A PR can change while a scan is still running.
Design for that reality:
- Use commit SHA as the decision key, not just PR number.
- Make scan requests idempotent.
- Cancel stale scans when a newer commit arrives.
- Store rule results with tool version and policy version.
- Require the check that passed to match the commit that merges.
- Keep webhook processing separate from scan execution.
Related reading from our network: payment teams solve similar state problems with retries, settlement, and webhooks; the architecture discussion in AI content blockchain payment workflows is adjacent because both domains fail when UI events are treated as final state.
SARIF, comments, and dashboards
SARIF is useful for code scanning integration. PR comments are useful for developer action. Dashboards are useful for program oversight. They are not interchangeable.
Use each for what it is good at:
- SARIF for structured findings and security tab visibility.
- PR checks for merge decisions.
- PR comments for concise remediation guidance.
- Dashboards for coverage, exceptions, bypasses, and trends.
- Tickets for remediation work that cannot happen in the PR.
What fails is making the dashboard the primary control. Dashboards are where findings go to age. The PR is where findings are still cheap to fix.
Metrics that prove the service is helping
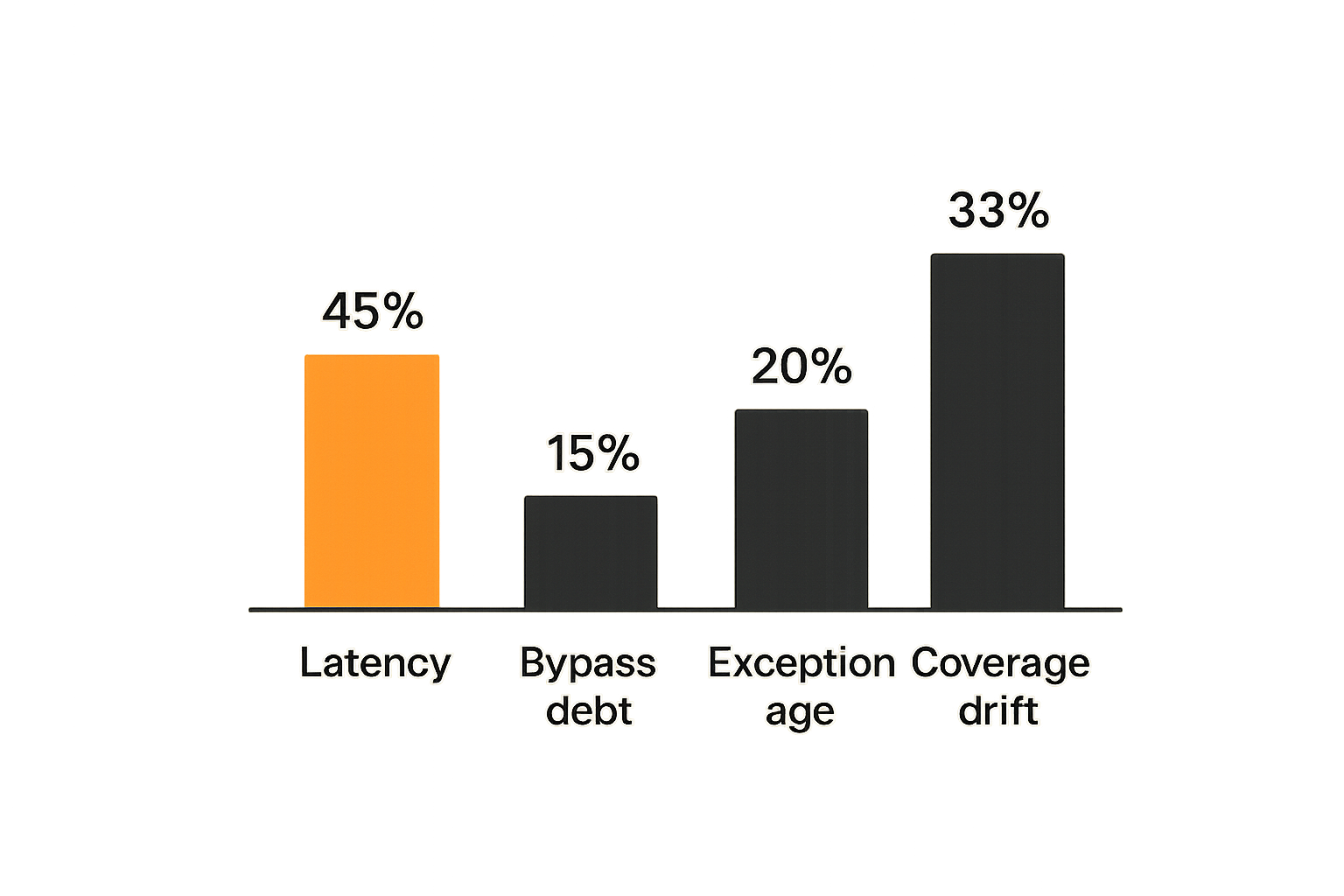
Measure decision latency
A security service should shorten the time between risky change and security decision. That is the first metric.
Track:
- Time from PR open to scan start.
- Time from scan start to check result.
- Time from failed check to owner action.
- Time from security review request to decision.
- Time from exception request to approval or rejection.
The goal is not to make every security decision instant. The goal is to remove avoidable waiting. If scans take thirty seconds but reviews take four days, the service is not the bottleneck. Ownership is.
Measure bypass and exception debt
Bypasses are not inherently bad. They are signals. If a team repeatedly bypasses the same rule, one of three things is true:
- The rule is too noisy.
- The architecture needs remediation.
- The team is accepting risk without enough scrutiny.
Track exceptions by rule, repo, owner, age, and expiration status. Review them like production error budgets. If exception debt only grows, your service is documenting risk, not reducing it.
Measure coverage drift
CI/CD environments drift. New repositories appear. Workflows get copied. Package managers change. Teams add release jobs. Permissions expand during incident response and never shrink.
Coverage metrics should answer:
- Which protected repos lack required checks?
- Which release workflows are not scanned?
- Which repos have package manifests but no package-diff enforcement?
- Which workflows use self-hosted runners without the right policy?
- Which branch protection rules allow admins to bypass required checks?
Coverage drift is where a service becomes a program. It keeps the control attached to the delivery system as the delivery system changes.
Product fit: vu1nz.com as a CI/CD security service layer
Where vu1nz.com fits
vu1nz.com is aimed at the part of the security service where many teams have a real gap: PR-time CI/CD workflow security and package supply-chain scanning. The product shape is intentionally narrow. One GitHub Action, workflow checks, and package review on newly introduced dependencies.
That makes it useful when you want to add enforcement without building a full internal service first. It can sit beside CodeQL, Dependabot, secret scanning, SCA, and artifact signing. The point is not to replace every security tool. The point is to catch the classes those tools often miss at the point where they become merge risk.
Good product fit:
- GitHub Actions-heavy teams.
- Repos that publish npm, pip, cargo, gem, Go, or Composer packages.
- Organizations with many workflow files and inconsistent permissions.
- Teams that already use Dependabot but want package-introduction scrutiny.
- DevSecOps groups trying to turn supply-chain policy into PR checks.
If you need public writeups and research context for the kinds of issues the team looks for, the vu1nz.com advisory style is intentionally PoC-driven rather than compliance-driven.
Where it should not be the only control
No CI/CD security service should be the only control. You still need:
- Branch protection.
- Required reviews and CODEOWNERS.
- Secret scanning.
- Artifact signing and provenance.
- Environment protection for deployments.
- Runtime detection.
- Incident response paths.
- Package registry controls.
The right architecture is layered. A PR-time service reduces the chance that risky changes merge. It does not eliminate the need to detect compromise, rotate credentials, validate artifacts, or investigate anomalous behavior after deployment.
The practical question is where to put the next control so it changes outcomes. If developers are adding packages and modifying workflows faster than security can review them, PR-time scanning is usually a high-leverage layer.
Closing: make the security service enforceable
The practical checklist
A security service only matters if it changes the path from risky change to safe merge. For CI/CD and supply-chain defense, that means the service must be close to the PR, aware of workflow authority, skeptical of new packages, and connected to branch protection.
Use this checklist:
- Define the risky changes you will block before writing broad policy.
- Treat privileged workflows as production-adjacent attack surface.
- Inspect package additions before install, build, and release jobs execute them.
- Route findings to owners, not generic security queues.
- Keep evidence in the PR.
- Make exceptions scoped and expiring.
- Measure decision latency, bypass debt, and coverage drift.
- Keep point tools, but do not let each one invent its own workflow.
Teams think the problem is buying a better scanner. The real problem is building a security service that can make timely, explainable, enforceable decisions inside the delivery path.
That is the standard to hold the architecture to in 2026.
Try vu1nz.com
vu1nz.com is for security engineers and DevSecOps teams who need to defend CI/CD pipelines and software supply chains from modern attacks. Try vu1nz.com.
Catch the next supply-chain attack on the PR that adds it.
14-day free trial · no card required