A deployment fails at 2 a.m. Someone adds a broad cloud role to get the release out. The incident is closed, the exception stays, and six months later that role is reachable from a CI job that also runs untrusted pull request code.
That is where identity and access management for cloud security gets real. Not in the IAM dashboard. Not in a quarterly spreadsheet. In the path between source code, CI/CD runners, package installation, artifact publishing, cloud deployment, and production response.
Teams think the problem is too many permissions. The real problem is that permissions are disconnected from workflows, ownership, and threat models.
That changes the conversation. IAM is not just a compliance control. For DevSecOps teams, it is the architecture that decides whether a compromised build script becomes a production incident, whether a malicious dependency can reach deployment credentials, and whether an attacker can turn one leaked token into cloud control-plane access.
Table of contents
- Why identity and access management for cloud security is now a pipeline problem
- The IAM architecture DevSecOps teams actually need
- Build a cloud access inventory that engineers will maintain
- What good cloud IAM policies look like
- CI/CD identity patterns that reduce blast radius
- Detection and response for IAM failures
- Implementation workflow for cloud IAM hardening
- Common failure modes in IAM programs
- How IAM connects to software supply-chain security
- Where vu1nz.com fits in the workflow
Why identity and access management for cloud security is now a pipeline problem
Static identities outlived their threat model
The mistake teams make is treating cloud IAM as if the main risk is a careless human clicking around the console. That risk still exists, but it is no longer the center of gravity.
Modern cloud access is exercised by automation: GitHub Actions, deployment bots, Terraform runners, container build systems, package publishing jobs, preview environment controllers, observability agents, and incident response scripts. Those systems run more often than humans do, touch more infrastructure, and often have weaker contextual controls.
A static cloud access key in a CI variable might have been acceptable when deployment was a monthly event from a locked-down build server. It is a bad fit for 2026 pipelines where runners are ephemeral, workflows are modified in pull requests, dependencies execute install scripts, and secrets can cross trust boundaries through logs, caches, artifacts, and third-party actions.
Practical rule: if an identity is used by automation, its permissions should be tied to the job, repository, branch, environment, and event that actually need it.
The cloud control plane is a deployment system
Cloud IAM is not a side panel attached to infrastructure. It is the control plane for changing infrastructure.
If a principal can update functions, attach policies, modify container tasks, write to artifact registries, assume roles, alter key policies, or edit workload identity bindings, it can often change what production runs. That means IAM decisions are deployment decisions.
The practical question is not, "Does this team need access?" It is, "Which workflow needs this access, under which conditions, for how long, and what can it change next?"
That framing catches issues a permissions review misses. A role with limited compute permissions may still be dangerous if it can change the image tag used by production. A package publishing token may not look like cloud access, but if production automatically deploys the latest internal package, that token influences runtime behavior.
IAM is where supply-chain risk becomes runtime risk
Software supply-chain attacks usually start upstream: malicious packages, compromised maintainer accounts, poisoned build steps, unsafe GitHub Actions, or dependency confusion. They become cloud incidents when the compromised code path reaches an identity with useful permissions.
That is the bridge IAM controls.
A malicious dependency installed during CI cannot deploy production by itself. It needs credentials, tokens, OIDC trust, a writable artifact path, or access to a job that has those things. If the pipeline identity is tightly scoped and separated by event type, branch, environment, and repository, the attacker has less room to move.
If the same broad deploy role is available to tests, linting, preview environments, and release builds, supply-chain compromise becomes a cloud security problem very quickly.
The IAM architecture DevSecOps teams actually need
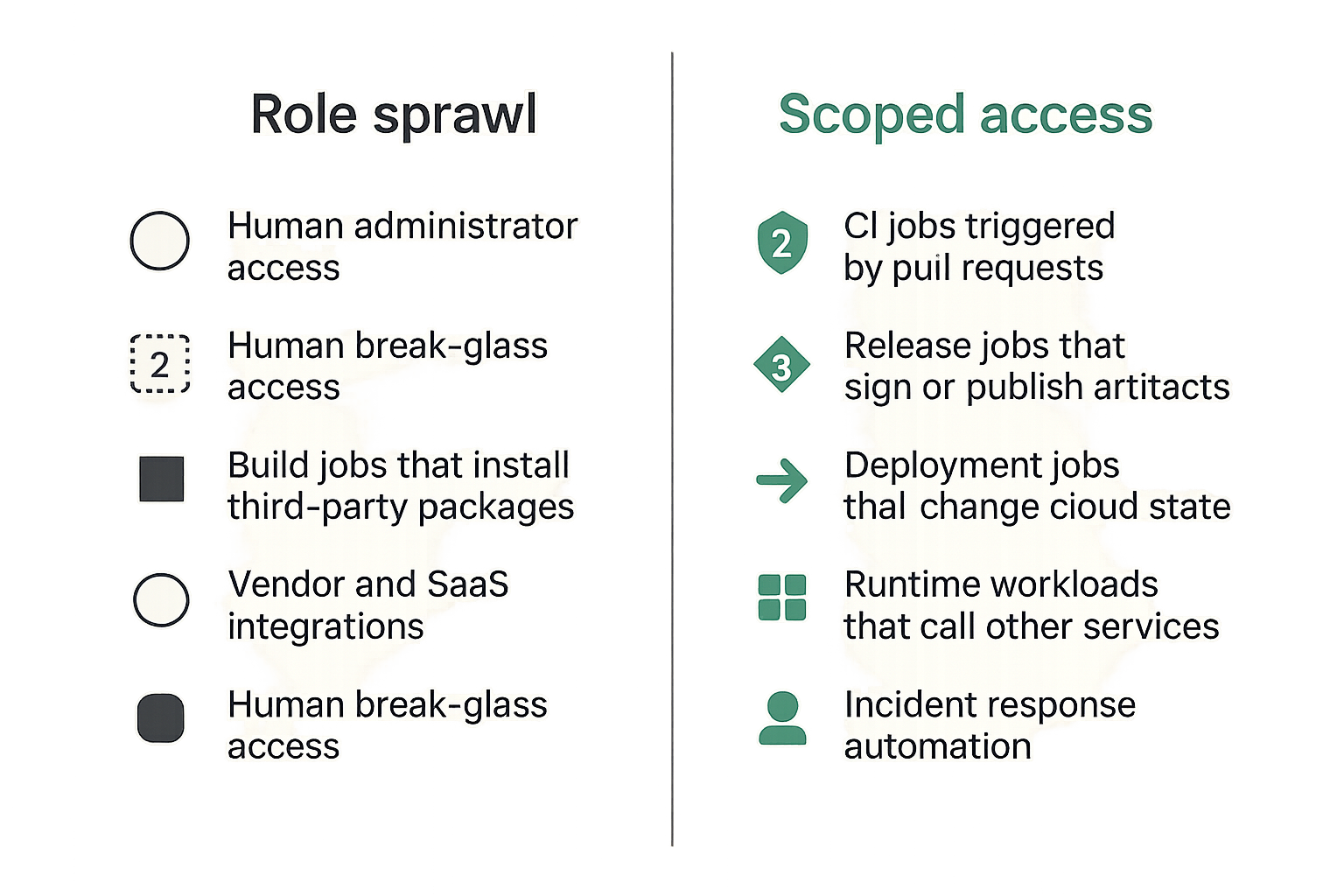
Start with trust boundaries
A useful way to think about it is to draw trust boundaries before you draw roles. Most IAM programs start from the wrong end: they enumerate policies, then try to simplify them. That produces cleaner-looking sprawl, not safer access.
Start with boundaries:
- Human administrator access
- Human break-glass access
- CI jobs triggered by trusted branches
- CI jobs triggered by pull requests
- Build jobs that install third-party packages
- Release jobs that sign or publish artifacts
- Deployment jobs that change cloud state
- Runtime workloads that call other services
- Vendor and SaaS integrations
- Incident response automation
Each boundary should have a different assumption about code trust, identity assurance, network path, logging, and blast radius. Related reading from our network: teams designing remote collaboration systems face the same access boundary problem across docs, meetings, support, and admin paths in cloud based productivity and collaboration tools architecture.
Map principals to jobs, not teams
Team-based roles are easy to explain and hard to secure. "Payments team admin" usually becomes a bundle of every permission anyone on the team might need during normal work, deployment, debugging, and emergencies.
Job-based roles force a better question: what is this identity doing?
| Approach | Looks efficient because | Breaks when | Better pattern |
|---|---|---|---|
| Team admin role | One role covers many tasks | A low-risk task inherits high-risk permissions | Separate roles for deploy, read-only debug, incident response |
| Shared CI secret | Easy to reuse across repos | Any workflow leak affects every environment | OIDC federation per repo, branch, and environment |
| Broad vendor role | Integration setup is fast | Vendor token compromise reaches unrelated resources | Vendor role scoped to exact APIs and resources |
| Manual exception policy | Unblocks urgent work | Nobody removes it | Time-bound role with owner and expiry |
The practical IAM unit is not a department. It is an execution path.
Separate human, workload, and vendor access
Humans need strong authentication, just-in-time access, auditability, and safe break-glass. Workloads need short-lived credentials, stable service identity, and narrow machine permissions. Vendors need constrained integration roles, explicit data boundaries, and contractually understood responsibilities.
Mixing these creates confusing risk. A human role used by CI bypasses human controls. A workload role used by an engineer hides accountability. A vendor role reused internally turns a third-party integration into a general-purpose backdoor.
Related reading from our network: AI agent execution creates similar identity problems because autonomous workloads need routing, validation, and constrained authority; the architecture tradeoffs are explored in AI agents cloud computing and decentralized execution.
Practical rule: every identity should have a type. Human, workload, CI job, vendor, or emergency. If you cannot name the type, you cannot reason about the blast radius.
Build a cloud access inventory that engineers will maintain
Inventory identities from the deployment path
The inventory that matters is not a flat export of every cloud principal. That is useful for auditors and painful for engineers. Start from the deployment path and walk outward.
For each production service, document:
- Source repositories that can change it
- CI workflows that build, test, release, or deploy it
- Package managers and registries used during build
- Artifact stores and signing systems
- Cloud roles assumed by CI
- Runtime service accounts or instance profiles
- Secrets and KMS keys reachable from those identities
- Humans who can approve or bypass deployment
This creates a map of how code becomes cloud state. It also exposes privilege inheritance. A repository maintainer may indirectly control production if they can edit a workflow that assumes a deploy role. A package maintainer may indirectly control runtime if an install script can run before artifact signing.
Track permissions with ownership and expiry
A permission without an owner becomes permanent. A permission without an expiry becomes architecture.
For every privileged identity, track four fields in a place engineers actually use: owner, purpose, expiry or review date, and validation method. That can live in Terraform metadata, a YAML registry, a service catalog, or policy-as-code comments. The format matters less than whether pull requests update it.
Example ownership record:
identity: gha-prod-api-deploy
kind: ci-workload
owner: platform-security
repository: org/api-service
allowed_events:
- push: main
- workflow_dispatch: release-managers
purpose: deploy api service to production
review_after: 2026-09-01
validation:
- oidc_subject_matches_repo_and_branch
- no_pull_request_events
- cloudtrail_alerts_on_policy_change
What breaks in practice is not that teams forget IAM exists. They forget why a role exists. Once purpose is gone, nobody is willing to remove it.
Use findings to change code review
An inventory only helps if it changes engineering behavior. The most useful output is not a dashboard. It is context in code review.
If a pull request changes a GitHub Actions workflow that can request cloud credentials, reviewers should see that fact. If Terraform adds iam:PassRole, reviewers should know which roles can be passed and what they can do. If a package is added to a build job with deployment credentials, that is not just dependency hygiene; it is identity exposure.
This is where DevSecOps should be skeptical of passive visibility tools. Visibility is table stakes. The operational win is putting identity context where changes happen.
What good cloud IAM policies look like
Prefer narrow actions over narrow intentions
Policy names lie. Intentions drift. Actions execute.
A policy called ReadOnlyDeploymentSupport may still include write actions added during an outage. A role named staging-deploy may have access to production KMS keys because a shared module made it convenient.
Good IAM policy design starts with explicit action sets. For cloud deployment roles, split permissions by operation:
- Read current state
- Publish artifact
- Update service configuration
- Migrate database schema
- Invalidate cache
- Rotate secret
- Roll back release
- Modify IAM
The last item should be rare. A deploy role that can freely modify IAM can often grant itself everything else.
Practical rule: deployment automation should not manage its own privilege boundary unless you have a deliberate bootstrap workflow with separate approval and monitoring.
Scope by resource, condition, and environment
Resource scoping is necessary but not enough. Conditions are where modern IAM becomes useful.
For CI/CD federation, condition on claims such as repository, branch, workflow, environment, audience, and event type. For runtime workloads, condition on service account, namespace, workload identity, network context, or resource tags. For human access, condition on device posture, MFA, session duration, and just-in-time approval.
A simplified AWS-style OIDC trust policy might look like this:
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::123456789012:oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com",
"token.actions.githubusercontent.com:sub": "repo:example/api-service:ref:refs/heads/main"
}
}
}
That policy is not complete for every environment, but the idea is important: the role is not available to any workflow in any branch. It is bound to a specific source context.
Make deny policies boring and explicit
Deny controls should be boring. They should encode rules that almost nobody argues with:
- CI roles cannot create new admin users.
- Pull request workflows cannot request production credentials.
- Staging roles cannot decrypt production secrets.
- Vendor roles cannot modify IAM policies.
- Runtime workloads cannot write to deployment artifact registries.
- Build jobs cannot disable logging or delete audit trails.
Deny policies are not a replacement for least privilege. They are guardrails for mistakes and future drift. The best deny policies protect boundaries that are unlikely to change.
CI/CD identity patterns that reduce blast radius
Replace long-lived secrets with federation
Long-lived cloud keys in CI are a liability. They are hard to scope to workflow context, hard to rotate safely, and easy to leak through logs, caches, artifacts, or compromised dependencies.
Federated workload identity changes the model. Instead of storing a cloud secret, the CI platform requests a short-lived token. The cloud provider validates claims about the repository, branch, workflow, and audience before issuing temporary credentials.
A minimal GitHub Actions permissions block should also be explicit:
permissions:
contents: read
id-token: write
actions: read
Do not leave broad defaults because a job might need them later. Make every permission request visible in review. If a workflow needs id-token: write, reviewers should ask what role it can assume and under which claims.
For a deeper CI/CD-specific implementation, we previously wrote about how the vu1nz GitHub Action catches workflow security issues before merge in Ship Safer with vu1nz GitHub Actions.
Design one deploy role per trust level
One production deploy role per cloud account sounds clean. In practice it becomes a dangerous choke point. Too many jobs need it, so teams add exceptions until it is reachable from places that should never touch production.
Use trust levels instead:
- Pull request validation: no production access
- Main branch build: can publish non-deployable artifacts
- Release job: can sign and promote artifacts
- Staging deploy: can update staging resources
- Production deploy: can update specific production services
- Emergency rollback: can roll back without broad administrative access
The point is not to create hundreds of roles. The point is to prevent low-trust code from reaching high-trust credentials.
Treat pull requests as untrusted compute
Pull requests are attacker-controlled input. That is true for public repositories, but it is also true internally when compromised developer accounts, fork settings, reusable workflows, or dependency scripts enter the picture.
A pull request workflow should not receive production cloud credentials. It should not receive package publishing tokens. It should not be able to write trusted artifacts consumed by deployment. It should not be able to poison caches used by release jobs.
Related reading from our network: secure messaging systems face a comparable boundary problem around keys, metadata, and operational workflows; the tradeoffs in end to end encryption messaging architecture are useful adjacent reading for teams thinking about key custody and trust separation.
Detection and response for IAM failures
Signals worth collecting
IAM detection works best when it is tied to workflow context. Raw cloud audit logs are necessary, but noisy. Enrich them with repository, workflow, actor, commit SHA, environment, and deployment metadata whenever possible.
Collect these signals first:
- Role assumption events
- Failed role assumption events
- Policy attachment, detachment, and edits
- Creation of access keys or service account keys
- Changes to OIDC providers and trust policies
- Use of break-glass roles
PassRoleor equivalent delegation events- KMS key policy changes
- Disabling or deleting logs
- Deployment from unexpected branches or workflows
The best detection is boring and specific: this role is normally assumed only by this workflow on this branch, but today it was assumed from a different subject.
What to alert on first
Alert fatigue kills IAM programs. Start with high-signal events that cross trust boundaries.
Alert when:
- A CI role is assumed from an unexpected repository, branch, or workflow.
- A pull request workflow requests cloud federation.
- A deployment role modifies IAM permissions.
- A new long-lived access key is created for an automation identity.
- A vendor role accesses resources outside its expected scope.
- A human assumes break-glass outside an incident ticket.
- Logging, audit trails, or security monitoring are disabled.
Do not start by alerting on every permission denied event. Some denied events are useful for tuning, but they are often too noisy for primary paging.
Response actions that do not break production
The hard part of IAM response is containment without self-inflicted outage. If the only response is "delete the role," teams will hesitate.
Prepare safer response actions:
- Disable federation for one repository subject.
- Remove a single branch or workflow claim from a trust policy.
- Shorten session duration temporarily.
- Detach a high-risk policy while leaving read-only diagnostics.
- Rotate package publishing tokens.
- Freeze artifact promotion while allowing service rollback.
- Require manual approval for production deploy until investigation closes.
What works is a response playbook that matches how deployment actually operates. What fails is an IAM incident process written by people who never deploy production.
Implementation workflow for cloud IAM hardening
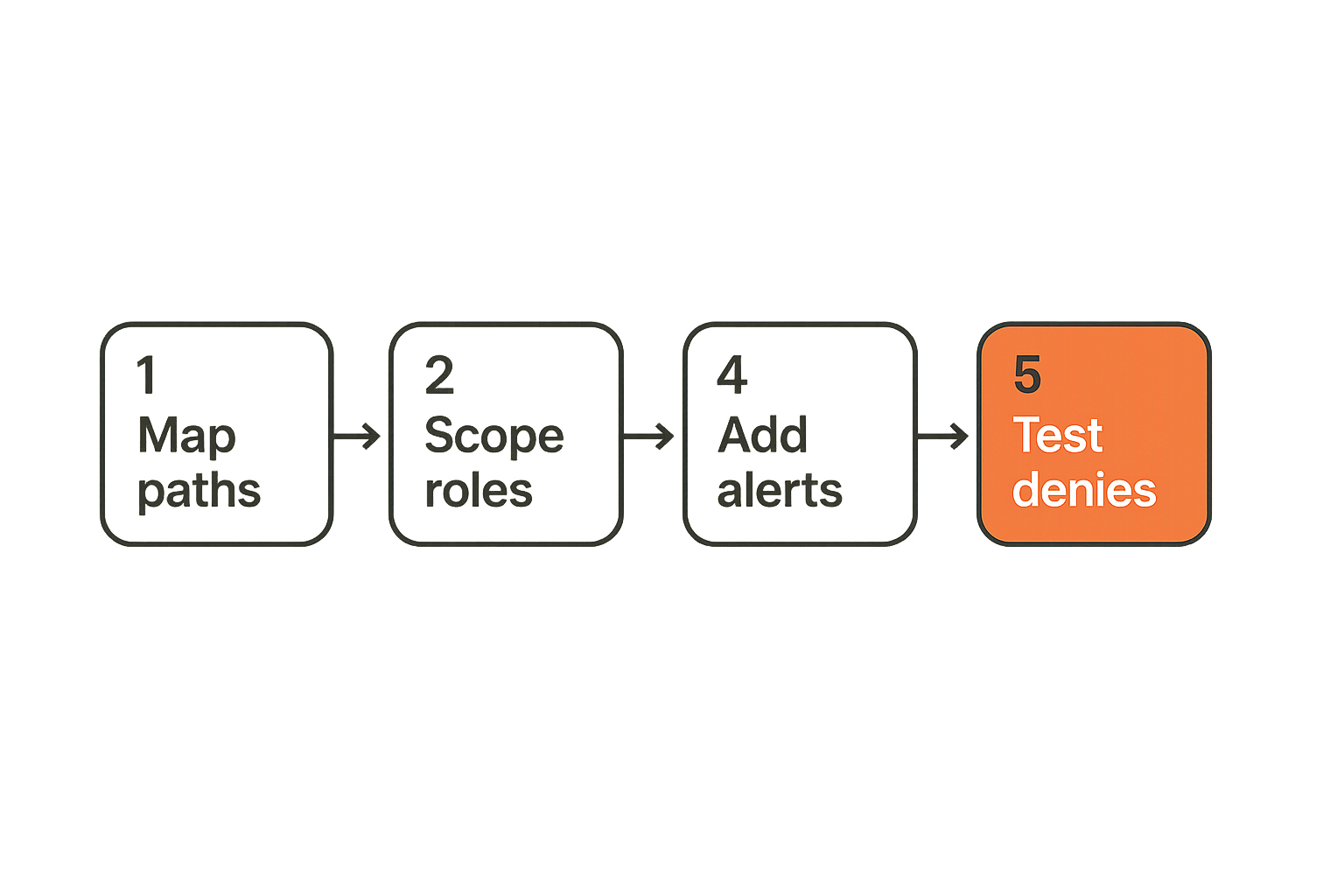
A 30-day rollout sequence
IAM hardening fails when teams try to fix the whole cloud estate at once. Start with one production deployment path and make the pattern repeatable.
- Pick a critical service with an active CI/CD pipeline.
- Map source repository, workflows, artifact path, deploy roles, runtime roles, and human approvers.
- Identify every identity reachable from pull request workflows, dependency installation, build steps, release steps, and deployment steps.
- Remove long-lived cloud secrets from CI where federation is available.
- Split deploy roles by trust level: PR, main build, release, staging deploy, production deploy.
- Add conditions to federation trust policies for repository, branch, workflow, and environment.
- Add deny guardrails for obvious boundary violations.
- Add logging and alerts for role assumption, policy changes, and unexpected subjects.
- Add policy-as-code checks to prevent regression.
- Document owner, purpose, expiry, and validation for every privileged identity.
This is intentionally narrow. Once the workflow works for one service, apply it to the next. The goal is a repeatable access pattern, not a heroic cleanup project.
Policy-as-code review gates
Policy-as-code should block dangerous changes before they become cloud state. But the gate needs to be specific enough that engineers trust it.
Good gates catch patterns like:
- Adding wildcard actions to production roles
- Allowing
iam:*or equivalent from CI roles - Trusting all branches or all repositories in OIDC conditions
- Adding long-lived access keys for automation users
- Allowing pull request events to assume deploy roles
- Attaching admin policies to vendor identities
- Creating roles without owner metadata
What fails is a generic scanner that dumps fifty medium findings into every infrastructure PR. Engineers learn to ignore it. Focus on rules that protect the boundaries you actually care about.
Validation with negative tests
Do not assume a policy works because it looks right. Test that forbidden paths fail.
Examples:
- A pull request workflow attempts to request an ID token and assume the production role. It should fail.
- A staging deploy role attempts to decrypt a production secret. It should fail.
- A runtime workload attempts to write to the artifact registry. It should fail.
- A vendor role attempts to list unrelated production resources. It should fail.
- A deployment role attempts to attach an administrator policy to itself. It should fail.
Negative tests are especially useful after refactors. They catch the "shared module made everything broader" class of bug.
Common failure modes in IAM programs

The admin role nobody owns
Every organization has one: a legacy admin role used by a deployment script, an engineer, a vendor integration, and an emergency runbook. Nobody wants to remove it because nobody knows what will break.
This role is not just overprivileged. It is a dependency. Treat it like one.
First, log every assumption and action. Then identify workflows using it. Then replace one usage at a time with scoped roles. Do not start by deleting it unless you are prepared for an outage.
Practical rule: the most dangerous IAM role is not always the broadest one. It is the broad role that is still on a critical path and has no accountable owner.
The exception path becomes the platform
Exceptions are necessary. They become dangerous when they are easier than the normal path.
If requesting a scoped deploy role takes two weeks but getting temporary admin takes one Slack approval, engineers will use admin. If policy-as-code blocks a release but the bypass is undocumented and unreviewed, the bypass becomes your real deployment system.
Make the safe path faster:
- Predefine common role templates.
- Provide self-service requests with owner and expiry fields.
- Keep emergency access time-bound.
- Review bypasses like production incidents.
- Convert repeated exceptions into supported workflows.
What works is making least privilege operationally usable. What fails is telling engineers to wait while production is down.
Tool output without an owner
IAM tools can produce impressive graphs and alarming findings. Many teams buy visibility and still do not reduce risk because nobody owns remediation.
Every finding needs routing:
- Infrastructure code issue: platform team
- Workflow permission issue: repository owner
- Runtime role issue: service owner
- Vendor access issue: procurement plus security owner
- Human access issue: identity team
- Break-glass issue: incident response owner
Without routing, IAM findings become background noise. With routing, they become pull requests, tickets, tests, or playbook changes.
How IAM connects to software supply-chain security
Dependencies can become identities
A dependency is not an identity in the cloud IAM sense. But during build, it can execute with the identity of the job installing it. That is the operational reality.
If npm install, pip install, cargo build, or a GitHub Action runs before credential isolation, that code may see environment variables, file-system tokens, cache contents, package registry credentials, or cloud federation capabilities. The package did not need its own account. It borrowed the pipeline's authority.
This is why supply-chain security and IAM cannot be separated. Dependency review tells you what code entered the build. IAM tells you what that code could reach.
We have covered this gap from the dependency side in What Dependabot Misses, especially the attacks that did not have a CVE when teams needed to make a decision.
GitHub Actions permissions are cloud permissions
GitHub Actions settings often look like repository hygiene. In a cloud-connected pipeline, they are part of cloud access control.
Watch for:
id-token: writein jobs that do not need cloud federationpull_request_targetworkflows running untrusted code paths- Third-party actions pinned to mutable tags instead of commit SHAs
- Workflow changes that alter deployment conditions
- Reusable workflows that hide credential use
- Caches shared between untrusted and trusted jobs
- Artifact uploads from low-trust jobs consumed by release jobs
The mistake teams make is reviewing workflow YAML as CI configuration only. Review it as IAM configuration. A one-line permission change can create a new path to cloud credentials.
Provenance only matters if access enforces it
Artifact signing, SBOMs, SLSA-style provenance, and attestations are useful. But they do not help much if your deployment role will deploy anything from anywhere.
Provenance needs enforcement:
- Only release workflows can sign deployable artifacts.
- Production deploy roles only accept artifacts from trusted registries.
- Runtime admission checks verify signatures and expected builders.
- CI roles cannot overwrite signed artifacts after promotion.
- Package publishing identities are separate from deployment identities.
That changes the conversation from "Do we have provenance?" to "Can an attacker bypass provenance by using another identity?"
Where vu1nz.com fits in the workflow
Use CI findings to prevent identity escalation
vu1nz.com is built for security engineers and DevSecOps teams defending CI/CD pipelines and software supply chains. That means we care about the point where workflow changes become access changes.
In practice, the valuable signal is not just "this workflow has a risky setting." It is "this risky setting can expose a path to credentials, package publishing, artifact promotion, or cloud deployment." That is the connection teams need in review, before a misconfiguration merges.
Pair package scanning with IAM boundaries
Package risk and IAM risk reinforce each other. A suspicious new dependency in a job with no secrets and no deployment path is still worth reviewing, but the blast radius is different. The same dependency in a release job with cloud federation, package publishing, and artifact signing deserves immediate attention.
A practical security workflow pairs both views:
- What new code or package entered the pipeline?
- Which workflow executes it?
- What credentials or tokens are available there?
- Can that job publish, sign, deploy, or assume a role?
- Are trust conditions tight enough to contain compromise?
That is the operator view of identity and access management for cloud security: not a static permission matrix, but a live map of how code gains authority.
Try vu1nz.com
vu1nz.com helps security engineers and DevSecOps teams defend CI/CD pipelines and software supply chains from modern attacks. If you want CI workflow checks and package risk scanning before risky changes merge, Try vu1nz.com.
Catch the next supply-chain attack on the PR that adds it.
14-day free trial · no card required