ADT security gets messy when teams treat it like another alert feed. A scanner flags a suspicious workflow change. Dependabot opens a version bump. A new npm package appears in a pull request. The SOC sees nothing because nothing has shipped yet. The developer sees noise because the finding lacks context.
Teams think the problem is detection coverage. The real problem is deciding what must happen between detection and merge.
That changes the conversation. For CI/CD and software supply chain teams, ADT security is not a consumer alarm metaphor and it is not a dashboard project. A useful way to think about it is automated detection and triage security: the operating layer that turns pipeline signals into consistent engineering decisions.
The practical question is simple: when a pull request changes build logic, secrets handling, permissions, or package inputs, who decides whether it is safe to merge, using what evidence, and with what enforcement path?
Table of contents
- Why ADT security belongs in the pipeline
- ADT security as an architecture not a tool
- What ADT security must detect before merge
- How to model ADT security signals
- The ADT security workflow that actually holds
- What works and what fails in ADT security
- GitHub Actions and package ecosystems are the hard part
- Metrics that make ADT security operable
- Failure modes that break ADT security programs
- Product fit for vu1nz.com
Why ADT security belongs in the pipeline
Most security programs already have detection somewhere. They have EDR on endpoints, SIEM rules for cloud logs, SCA for dependencies, secret scanning, and a backlog of policy exceptions. What they often do not have is a reliable control loop at the point where software supply chain risk is introduced.
For modern teams, that point is the pull request.
The merge request is the control point
The pull request is where intent, code, configuration, identity, and review all meet. A CI/CD workflow change can grant a job broader token permissions. A lockfile update can introduce a maintainer-compromised package. A build script can exfiltrate an environment variable. A release job can publish an artifact built from untrusted input.
The mistake teams make is treating these as separate categories. In practice, attackers chain them. A malicious package does not need to exploit production if it can run during install in CI. A compromised workflow does not need a zero-day if it can request write permissions and push a release. A leaked token is worse when the pipeline can mint artifacts trusted by downstream systems.
Practical rule: If a change can alter what runs in CI or what CI is allowed to access, treat it as security-relevant before merge.
This is why ADT security belongs inside the pipeline. It should not wait for a runtime symptom. It should inspect the proposed change, classify the risk, route the decision, and block or allow based on rules the team can defend.
Runtime alerts arrive too late
Runtime monitoring still matters. But supply chain attacks often succeed before runtime systems have a useful signal. By the time a malicious package executes in production, the artifact may already be trusted, signed, cached, deployed, and replicated.
Pipeline-time detection is cheaper because the blast radius is smaller. You can still ask who introduced the dependency, why the workflow changed, whether the package is new to the organization, and whether the job permissions are necessary. After deployment, you are doing incident response.
Related reading from our network: teams building SOC workflows face the same detection-versus-ownership problem in social engineering security architecture, even though the signals are different.
ADT security as an architecture not a tool

Buying another scanner does not create ADT security. It creates another source of findings. The architecture is the part that decides how findings become engineering outcomes.
A useful ADT security architecture has four layers:
- Signal collection from workflows, dependency manifests, lockfiles, package metadata, secrets, permissions, and artifact paths.
- Normalization so every signal has a repository, actor, change context, severity, evidence, and recommended action.
- Decision logic that maps signals to allow, warn, require review, or block.
- Ownership routing so the right team can resolve the finding without a security archaeology project.
Detection without triage creates backlog
Detection is easy to overproduce. Every tool can find something. The hard part is deciding which findings matter for this pull request.
For example, a package with no CVE but suspicious install scripts may be more urgent than a low-severity CVE in a test-only transitive dependency. A workflow permission escalation in a release repository may matter more than the same pattern in a sandbox repository. A secret-looking string in documentation may be a false positive, while a token added to a test fixture may be real.
That is triage. It requires context.
| Approach | What it optimizes | What breaks in practice |
|---|---|---|
| Scanner-only security | More findings | Developers ignore repeated low-context alerts |
| Ticket-only triage | Central control | Security becomes a bottleneck and loses code context |
| Merge-time ADT security | Decisions at the change boundary | Requires clear ownership and exception rules |
| Runtime-only detection | Incident visibility | Supply chain compromise may already be deployed |
Triage without ownership creates drift
Triage also fails when no one owns the result. If security says investigate and engineering says it is just a dependency update, the pull request stalls or the rule gets bypassed. If platform engineering owns the workflow but application teams own the package manifest, findings bounce between teams.
You need ownership encoded in the workflow. Not necessarily a giant RACI spreadsheet, but clear routing:
- Workflow permission changes go to platform or CI owners.
- New direct dependencies go to the application team.
- Suspicious package behavior goes to security or DevSecOps.
- Release and signing changes go to release engineering.
- Policy exceptions require an expiry and a named owner.
The vu1nz GitHub Action is useful in this model because it runs where the decision is happening: on the pull request, against both CI/CD workflow risk and newly added package risk.
What ADT security must detect before merge
ADT security should not attempt to replace every security program. It should focus on risks that are introduced by code review and automation. The scope is narrower than all application security, but deeper than basic dependency scanning.
Workflow abuse and CI privilege paths
CI/CD workflows are executable infrastructure. They decide what code runs, what secrets are available, which tokens are minted, what artifacts are trusted, and which branches can be changed.
Signals worth detecting include:
- Pull request workflows that run untrusted code with privileged tokens.
- Overbroad token permissions such as write-all defaults.
- Use of pull_request_target without strict checkout controls.
- Unpinned third-party actions.
- Shell injection opportunities in workflow expressions.
- Jobs that expose secrets to forks or untrusted contributors.
- Release jobs that can be triggered from weak branch conditions.
These are not theoretical hygiene issues. They are control-plane problems. If an attacker can alter the pipeline, they may not need to exploit the application.
Package and dependency risk
Known vulnerability matching is necessary but incomplete. Many supply chain incidents begin before a CVE exists. The useful question is not only whether the package is known-bad. It is whether the package is unexpectedly new, behaves strangely, or has characteristics that require review.
Look for:
- New direct dependencies added in the pull request.
- Install scripts in npm packages or equivalent lifecycle hooks.
- Typosquatting and namespace confusion patterns.
- Recently published packages with thin history.
- Packages with unusual network, filesystem, or process behavior.
- Lockfile changes that do not match manifest intent.
If your current process only flags published CVEs, read our prior analysis of what Dependabot misses in npm supply chain attacks. The practical gap is not that CVE scanners are bad. The gap is that many attacks are not CVEs when they first matter.
Credential and artifact exposure
The pipeline is full of trust material. Tokens, signing keys, deployment credentials, package registry secrets, cloud role assumptions, and artifact attestations all move through CI/CD.
ADT security should detect changes that increase exposure:
- Secrets passed into jobs that run untrusted code.
- Credentials written to logs or artifacts.
- Build outputs uploaded from unreviewed branches.
- Publishing jobs that do not verify source branch and actor.
- Cache poisoning paths where attacker-controlled content is restored into privileged jobs.
Practical rule: Treat artifacts as security boundaries. If an untrusted job can influence a trusted artifact, the pipeline is part of the attack surface.
How to model ADT security signals
The fastest way to make ADT security noisy is to model every finding as an alert. Alerts imply urgency but not necessarily action. Pipeline security needs a decision model.
Separate facts from decisions
A fact is observable. A decision is policy.
Facts:
- This pull request adds package leftpad-example.
- This workflow changes permissions from read to write.
- This job runs on pull_request_target.
- This action is referenced by a mutable tag.
- This package has an install script.
Decisions:
- Block until reviewed by security.
- Require platform approval.
- Allow because repository is sandboxed.
- Warn but do not block.
- Open an issue for hardening.
When tools blur facts and decisions, teams either overblock or underreact. Keep the evidence visible. Let policy decide what the evidence means for a repository, branch, package ecosystem, and release path.
Use context to reduce false urgency
Context is not an excuse to ignore risk. It is how you avoid treating every repository the same.
Useful context includes:
- Repository criticality.
- Whether the workflow can access secrets.
- Whether the package is direct or transitive.
- Whether the dependency is runtime, dev, test, or build-time.
- Whether the actor is a maintainer, bot, first-time contributor, or external fork.
- Whether the change affects release, deployment, signing, or publishing.
For adjacent workflow thinking, remote teams face similar access and control tradeoffs when rolling out cloud based productivity and collaboration tools. Different domain, same lesson: permissions and workflow design matter more than the UI.
The ADT security workflow that actually holds

The workflow needs to be boring enough to survive normal engineering pressure. If it only works during a security initiative, it will fail when release deadlines return.
A practical implementation sequence
Start with a small control loop and make it reliable before expanding.
- Inventory CI entry points. List workflows, triggers, privileged jobs, release jobs, package publish jobs, and repositories that produce trusted artifacts.
- Define merge-time risk classes. Examples: workflow privilege escalation, unpinned action, new direct dependency, suspicious package behavior, secret exposure, artifact trust change.
- Choose enforcement levels. Use allow, warn, require owner review, and block. Do not make everything critical.
- Run detection on pull requests. Scan the diff, workflow files, manifests, lockfiles, and package metadata before merge.
- Attach evidence to the PR. Developers should see the file, line, reason, and suggested fix without leaving the review flow.
- Route approvals to owners. Platform owns workflow risk. App teams own dependency intent. Security owns suspicious behavior and exceptions.
- Track exceptions with expiry. A permanent exception is usually a policy failure disguised as velocity.
- Review misses and false positives. Tune policy based on incidents, bypasses, and developer feedback.
This sequence sounds basic. That is the point. ADT security works when it becomes part of the merge contract, not when it becomes a separate security ritual.
Where humans should stay in the loop
Automation should make decisions obvious, not pretend every decision is obvious.
Humans should review:
- First-time introduction of new build or release dependencies.
- Changes that grant write permissions to automation.
- New package publishers or registries.
- Unexpected install scripts or binary downloads.
- Release workflow changes near signing or deployment.
- Exceptions requested for privileged repositories.
Automation can handle:
- Known safe repository patterns.
- Repeat findings already accepted under a current exception.
- Low-impact warnings on non-release repositories.
- Formatting and evidence collection.
- Blocking obviously dangerous combinations.
Practical rule: Automate evidence gathering aggressively. Automate final approval only where the blast radius and policy are clear.
What works and what fails in ADT security
ADT security is not mature because the diagram looks clean. It is mature when it still works after developers add new workflows, package managers, monorepos, forks, bots, and emergency releases.
What works in production
The strongest programs tend to do a few simple things well:
- They run checks on every pull request that changes pipeline or dependency inputs.
- They keep findings close to the diff.
- They separate high-confidence blocks from advisory warnings.
- They assign ownership based on the type of risk.
- They treat dependency additions differently from dependency updates.
- They review workflow permissions as carefully as cloud IAM.
- They keep exceptions visible and time-bound.
This is also where good security research matters. Public writeups and reproducible findings help teams understand real exploit paths instead of arguing about abstract severity. The vu1nz team publishes practical research and advisories on the main CI/CD and package supply chain security blog, which is the right place to look when you want attack mechanics rather than vague best practices.
What fails after the first month
The failures are usually operational, not technical.
- Every finding is critical, so developers stop reading.
- Security owns all approvals, so reviews queue behind one team.
- The scanner reports package CVEs but misses new package behavior.
- Workflow checks ignore permissions, trigger context, and fork behavior.
- Exceptions have no owner or expiry.
- Results live in a dashboard nobody checks during code review.
- Bots open noisy tickets that are disconnected from the pull request.
The mistake teams make is thinking adoption means installation. Installation is day one. Adoption is when the control still affects merge decisions three months later.
GitHub Actions and package ecosystems are the hard part
GitHub Actions and package managers are convenient because they compose. That same composability is what makes them risky. A workflow can call an action that calls a script that installs a package that runs a lifecycle hook that reaches the network. The attack path crosses boundaries that many tools inspect separately.
Why CI configuration is executable attack surface
A workflow file is not passive configuration. It is code that controls execution, identity, and trust. Treating it as YAML housekeeping is how dangerous changes slide through review.
Reviewers should ask:
- What event triggers this workflow?
- Does it run code from the pull request?
- Which token permissions does it receive?
- Which secrets are available?
- Are third-party actions pinned to immutable references?
- Does the job publish, deploy, sign, or upload artifacts?
- Can cache state cross from untrusted to trusted execution?
Here is a simple policy sketch many teams adapt:
pull_request_rules:
workflow_changes:
require_review_from: platform-security
block_if:
- token_permissions_increase
- uses_pull_request_target_with_checkout
- third_party_action_not_pinned
dependency_additions:
require_review_from: owning-team
escalate_if:
- install_script_present
- package_new_to_org
- suspicious_metadata
The exact syntax does not matter. The operating model does.
Why known CVE matching is not enough
CVE scanners answer a narrow question: is this component known to have a disclosed vulnerability? That is useful, but supply chain attacks often abuse trust, naming, publishing, lifecycle scripts, or maintainer compromise before a vulnerability database can help.
ADT security needs pre-CVE reasoning. Not magic AI claims. Just evidence about package behavior, provenance, novelty, and execution context.
For example:
- A brand-new direct dependency in a build job deserves scrutiny even with no CVE.
- A package with an install script deserves different handling from a pure data package.
- A dependency added only to tests may still run in CI with secrets nearby.
- A transitive package may become important if the lockfile changes unexpectedly.
Related reading from our network: people evaluating security careers and AI-assisted work should understand this same shift toward workflow ownership in security jobs for AI-assisted freelancers. Tool usage matters less than whether the operator can drive a reliable decision process.
Metrics that make ADT security operable
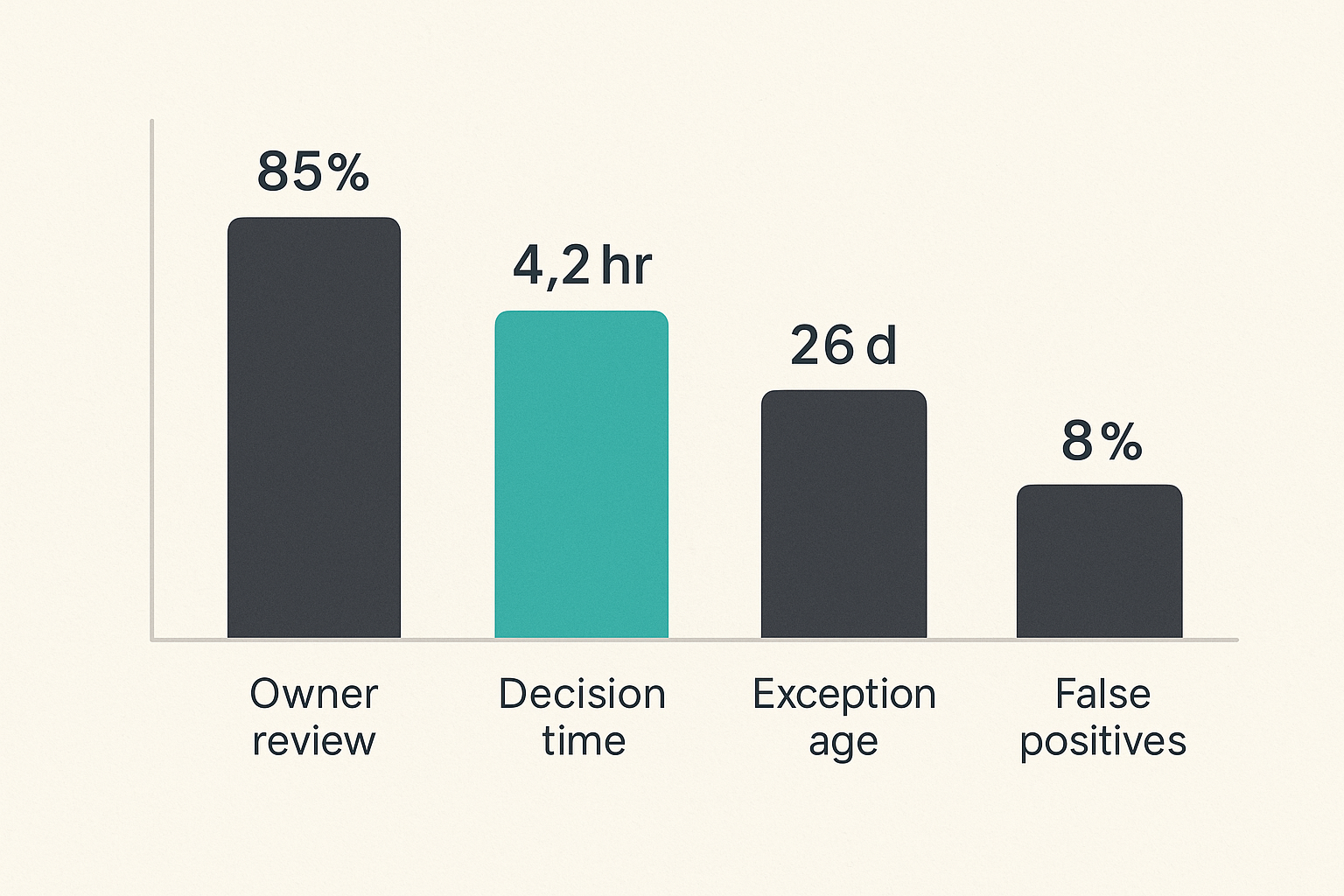
Metrics should help operators tune the workflow. If the metric only makes the dashboard look busy, it will not improve ADT security.
Measure decision quality not alert volume
Alert volume is a vanity metric unless paired with outcomes. A team can reduce alerts by turning off rules or increase alerts by enabling everything. Neither proves safer software.
Better metrics:
- Percentage of workflow-risk PRs reviewed by the right owner.
- Median time from finding to merge decision.
- Number of blocked high-risk workflow changes.
- Number of new direct dependencies reviewed before merge.
- Exception count by repository and age.
- False positive rate by rule.
- Findings reopened after bypass or revert.
The point is not to create a quarterly security theater report. The point is to see where the control loop is slow, noisy, or blind.
Track friction where developers feel it
Developer friction is not always bad. Some friction prevents incidents. The problem is unexplained friction.
Track where developers get stuck:
- Findings without clear remediation.
- Approval requests routed to the wrong team.
- Blocks that depend on undocumented policy.
- Repeated warnings that never change behavior.
- Scans that finish after reviewers already approved the PR.
- Rules that behave differently across repositories without explanation.
If you want ADT security to last, make the secure path the predictable path. Developers can tolerate a block when the reason is clear, the owner is obvious, and the fix is practical.
Failure modes that break ADT security programs
The common failure modes are boring. That is why they are dangerous. They do not look like a breach. They look like process decay.
The scanner graveyard
Many organizations have a graveyard of scanners that technically run but do not influence decisions. They post comments. They upload SARIF. They open tickets. Nobody knows which findings are blocking, which are advisory, and which are stale.
What breaks in practice is attention. Developers learn that security output is background noise.
Fix it by assigning each rule an enforcement mode and an owner. If a finding does not map to a decision, reconsider whether it belongs in the pull request path.
The silent bypass problem
Every control has bypass paths. Admin merges. Emergency releases. Disabled workflow runs. Generated lockfiles. Bot commits. Monorepo exceptions. Fork settings. Self-hosted runners with special access.
ADT security needs bypass visibility. Not every bypass is malicious. Some are legitimate. But silent bypasses destroy trust in the control.
Minimum viable bypass logging:
- Who bypassed.
- Which rule was bypassed.
- Which repository and pull request were affected.
- Why the bypass was used.
- When the exception expires.
Practical rule: A bypass without an owner and expiry is not an exception. It is a second policy.
The ownership gap
The ownership gap appears when a finding lands between teams. Security can explain the risk, but platform owns the workflow. Platform can fix the workflow, but the app team owns the dependency. The app team can remove the dependency, but product wants the feature.
You solve this with explicit routing and escalation rules. Do not wait for an incident to decide who owns CI token permissions or package admission decisions.
Product fit for vu1nz.com
ADT security for CI/CD is a control-loop problem: detect the risky change, explain the evidence, route the decision, and stop unsafe merges before they become production incidents. That is exactly where a narrow, pull-request-native tool can be more useful than a broad dashboard.
Where vu1nz fits in the architecture
vu1nz focuses on the merge boundary for CI/CD and package supply chain risk. The product model is intentionally direct: one GitHub Action, CI/CD workflow checks, and package scanning for new dependencies introduced in pull requests.
That means it fits best when you need to answer questions like:
- Did this PR weaken GitHub Actions security?
- Did it introduce a risky package before any CVE exists?
- Did it change workflow permissions, triggers, or action pinning?
- Did it add package behavior that deserves human review?
- Can we put evidence in front of the reviewer before merge?
It is not a replacement for runtime detection, SAST, code review, or incident response. It is the earlier control that reduces how often those teams discover supply chain risk after the fact.
When not to use another tool
Do not add another tool if you cannot decide what happens when it finds something. First define your enforcement modes, owners, and exception rules. Then wire in detection.
A good starting policy is:
- Block workflow privilege escalation in release repositories.
- Require review for new direct dependencies.
- Warn on unpinned actions in low-risk repositories, block in high-risk repositories.
- Escalate suspicious package behavior to DevSecOps.
- Expire exceptions automatically.
Once that policy exists, tooling has a job. Without it, tooling becomes another feed.
ADT security works when it turns CI/CD and package signals into merge-time decisions. If your team wants that control at the pull request boundary, vu1nz.com is built for exactly that closing gap.
Try vu1nz.com
You are writing for security engineers and DevSecOps teams who need to defend CI/CD pipelines and software supply chains from modern attacks. Try vu1nz.com.
Catch the next supply-chain attack on the PR that adds it.
14-day free trial · no card required